Kurs STM32 LL cz. 24. Komunikacja SPI w trybie DMA

Komunikacja z pamięcią SPI Flash w przypadku dużych ilości danych może być obciążająca dla jednostki CPU. Warto wtedy skorzystać z kontrolera DMA i bezpośredniego transferu danych z pamięci do rejestrów SPI.
Lista lekcji „Kurs STM32 Low Layer”
- Kurs STM32 LL cz. 1. Biblioteki Low Layer, Nucleo-G071RB, STM32CubeIDE
- Kurs STM32 LL cz. 2. Przygotowanie projektu
- Kurs STM32 LL cz. 3. Wewnętrzne i zewnętrzne źródła zegara
- Kurs STM32 LL cz. 4. Pętla PLL i taktowanie układów peryferyjnych
- Kurs STM32 LL cz. 5. Budowa GPIO i sterowanie wyjściem
- Kurs STM32 LL cz. 6. Wyjście GPIO i przerwania EXTI
- Kurs STM32 LL cz. 7. Interfejs USART, transmisja danych w trybie polling
- Kurs STM32 LL cz. 8. Komunikacja USART w trybie przerwań
- Kurs STM32 LL cz. 9. Kontroler DMA, komunikacja USART w trybie DMA
- Kurs STM32 LL cz. 10. Rodzaje i budowa Timerów, Timer w funkcji licznika
- Kurs STM32 LL cz. 11. Timer w trybie Input Capture
- Kurs STM32 LL cz. 12. Timer w trybie Output Compare i PWM
- Kurs STM32 LL cz. 13. Wstęp do konwertera ADC
- Kurs STM32 LL cz. 14. Konwersja ADC Single Channel i Multi Channel w trybie Polling
- Kurs STM32 LL cz. 15. Konwersja ADC Single Channel i Multi Channel w trybie przerwań
- Kurs STM32 LL cz. 16. Konwersja ADC Single Channel i Multi Channel w trybie DMA
- Kurs STM32 LL cz. 17. Wstęp do magistrali I2C
- Kurs STM32 LL cz. 18. Komunikacja I2C w trybie polling
- Kurs STM32 LL cz. 19. Komunikacja I2C w trybie przerwań
- Kurs STM32 LL cz. 20. Komunikacja I2C w trybie DMA
- Kurs STM32 LL cz. 21. Wprowadzenie do interfejsu SPI
- Kurs STM32 LL cz. 22. Komunikacja SPI w trybie polling
- Kurs STM32 LL cz. 23. Komunikacja SPI w trybie przerwań
- Kurs STM32 LL cz. 24. Komunikacja SPI w trybie DMA
Kontroler DMA
Zanim przejdziemy do przykładu, przypomnijmy sobie wiadomości na temat DMA i DMAMUX w STM32G071RB. Direct Memory Access (DMA), czyli mechanizm bezpośredniego dostępu do pamięci to technika przesyłania danych z pominięciem jednostki CPU.


DMA pozwala na przesyłanie danych:
- z pamięci do pamięci
- z pamięci do układu peryferyjnego
- z układu peryferyjnego do pamięci
- z układu peryferyjnego do układu peryferyjnego
W mikrokontrolerach STM32 możemy mieć do dyspozycji jeden lub dwa kontrolery DMA. Każdy kontroler ma kilka kanałów, a każdy kanał może obsługiwać różne rodzaje transferów. W STM32G071 dostępny jest jeden kontroler DMA1 z 7 kanałami.
To, jak zbudowany jest przepływ danych w STM32, przedstawia poniższa grafika.

Kontroler DMA podłączony jest do szyny AHB (Advanced High-Performance Bus), która komunikuje go z pamięcią SRAM i Flash oraz za pośrednictwem szyny APB (Advanced Peripheral Bus) z układami peryferyjnymi. Układem nadzorującym współpracę między szynami jest Bus Matrix.
W przypadku, gdy dwa kanały DMA chcą wykonywać transfer jednocześnie, Arbiter rozdziela czas dostępu do Bus Matrix dla każdego kanału.
Gdy dostępne są dwa oddzielne kontrolery DMA, mogą one korzystać z Bux Matrix jednocześnie, dopóki nie korzystają z tych samych układów peryferyjnych.

Szyna AHB implementuje algorytm karuzelowy (round robin), według którego przydziela dla każdego z układów przedział czasowy na wykonanie operacji, nie uwzględniając żadnych priorytetów. Kontroler DMA może więc spowolnić pracę CPU, jeżeli oba elementy potrzebują dostępu do tego samego obszaru pamięci lub układu peryferyjnego (zdarza się to bardzo rzadko). Nie może jednak zablokować CPU, ponieważ arbiter rozdziela po równo cykle pracy pomiędzy poszczególne elementy mikrokontrolera.
W starszych mikrokontrolerach (seria F i L) kontroler DMA podzielony jest na kanały. Do każdego z kanałów dołączonych jest kilka układów peryferyjnych i tylko jeden z nich może być jednocześnie obsługiwany jest dany kanał DMA.
W nowszych układach (seria G) do każdego z kanałów można podpiąć dowolny układ peryferyjny z dostępnych. Za zarządzanie odpowiada DMAMUX. DMAMUX pozwala także na użycie generatora DMA do układów peryferyjnych, które nie mają funkcji DMA.
DMA generuje trzy rodzaje przerwań:
- po wykonaniu połowy transferu
- po wykonaniu całego transferu
- w przypadku błędu
DMA może przesyłać dane po 8, 16 lub 32 bity (odpowiednio Byte, Half Word i Word). Szerokość danych zależna jest od rodzaju wysyłanych przez nas danych (po stronie pamięci) oraz od rozmiaru rejestru. Dodatkowo przed rozpoczęciem transferu DMA ustalany jest rozmiar, czyli ilość danych do przesłania.
Każdy transfer DMA może mieć przypisany jeden z 4 priorytetów, według których kontroler wykonuje transfery w przypadku, gdy jednocześnie wystąpi potrzeba obsługi dwóch lub więcej kanałów.
- very high
- high
- medium
- low
Poza tym kontroler DMA ma możliwość automatycznej inkrementacji adresów po stronie układu peryferyjnego i pamięci oraz możliwość cyklicznego transferu (po zakończeniu jednego rozpoczyna się kolejny od początku skonfigurowanego adresu – na zasadzie bufora kołowego). Pozwala to dobrać sposób przesyłania danych według potrzeb.
Rejestry DMA
Rejestr DMA_ISR – rejestr z flagami przerwań dla każdego z 7 kanałów


Rejestr DMA_IFCR – czyszczenie flag przerwań

DMA_CCRx – rejestr konfiguracyjny dla kanału x

Bity MEM2MEM – włączenie transferu pamięć-pamięć

Bit PL[1:0] – wybór priorytetu

Bity MSIZE[1:0] – rozmiar danych po stronie pamięci

Bity PSIZE[1:0] – rozmiar danych po stronie układu peryferyjnego

Bit MINC – włączenie zwiększania adresu po stronie pamięci

Bit PINC – włączenie zwiększania adresu po stronie układu peryferyjnego

Bit CIRC – tryb kołowy

Bit DIR – kierunek transferu

Bit TEIE – włączenie przerwania od błędu

Bit HTIE – włączenie przerwania od połowy transferu

Bit TCIE – włączenie przerwania od pełnego transferu

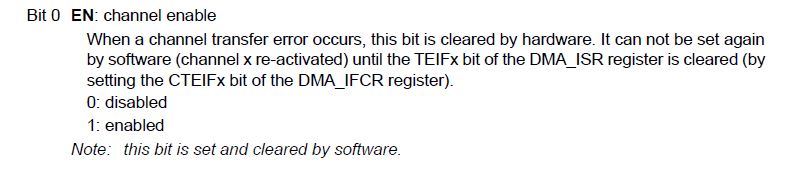
Bit EN – włączenie kanału
Rejestr DMA_CNDTRx – rozmiar transferu dla kanału x

DMA_CPARx – adres układu peryferyjnego dla kanału x

DMA_CMARx – adres układu pamięci dla kanału x


Multiplekser DMA
W układach z serii G do każdego z kanałów można podpiąć dowolny układ peryferyjny z puli dostępnych. Za zarządzanie przepływem danych odpowiada multiplekser, czyli DMAMUX.
DMAMUX ma za zadanie przekierować na wybrany kanał sygnał z układu peryferyjnego, którego chcemy użyć. Dzięki temu mamy dużą elastyczność pod względem używania DMA. Nie pojawi się problem często występujący w poprzednich seriach STM32 (np. F1), gdzie nie mogliśmy użyć dwóch peryferiów w trybie DMA, bo były podłączone do tego samego kanału.
W STM32G071 mamy do dyspozycji 77 wejść mogących korzystać z kontrolera DMA. Pełną listę przedstawia tabela.

Rodzaj wejścia dla kanału x konfigurujemy przy pomocy rejestru DMAMUX_CxCR i bitów DMAREQ_ID[6:0].


DMA w magistrali SPI
Na koniec przygody z magistralą SPI przyjrzyjmy się obsłudze komunikacji w trybie DMA. Poza znaną nam już konfiguracją kontrolera DMA i DMAMUX, rejestry SPI są pod względem DMA łatwe do ustawienia. Transfer DMA w SPI włączamy za pomocą dwóch bitów umieszczonych w rejestrze konfiguracyjnym CR2.


Wszystkie projekty z kursu dostępne są w moim repozytorium GitHub.
[PROGRAM] Komunikacja SPI w trybie DMA
Komunikację z użyciem kontrolera DMA obsłużymy w sposób analogiczny do trybu przerwań. Przykład wykonamy z pamięcią Flash W25Q64FV.
Aby zastąpić komunikację w trybie przerwań transferem DMA, dodajemy dwie funkcje w bibliotece do obsługi pamięci.
uint8_t W25Q64_SPI_Transmit_Data_DMA(uint8_t *data, uint16_t size)
{
spi_write_data_dma(data, size);
return 0;
}
uint8_t W25Q64_SPI_Receive_Data_DMA(uint8_t *data, uint16_t size)
{
spi_read_data_dma(data, size);
return 0;
}
Umieszczamy komunikację DMA w funkcjach W25Q64_ReadDataBytes oraz W25Q64_PageProgram. Po zmianach będą wyglądały jak poniżej.
uint8_t W25Q64_ReadDataBytes(uint32_t adress, uint8_t *data, uint16_t size)
{
uint8_t data_to_send[] = { 0, 0, 0, 0 };
uint8_t status;
W25Q64_WaitForWriteInProgressClear();
data_to_send[0] = READ_DATA;
data_to_send[1] = (adress >> 16) & 0xff;
data_to_send[2] = (adress >> 8) & 0xff;
data_to_send[3] = adress & 0xff;
W25Q64_Set_ChipSelect_Low();
W25Q64_SPI_Transmit_Data(data_to_send, 4);
status = W25Q64_SPI_Receive_Data_DMA(data, size);
//W25Q64_Set_ChipSelect_High();
return status;
}
uint8_t W25Q64_PageProgram(uint32_t page_adress, uint8_t *data, uint16_t size)
{
uint8_t data_to_send[] = { 0, 0, 0, 0 };
uint8_t status;
W25Q64_WaitForWriteInProgressClear();
W25Q64_WriteEnable_and_WaitForWriteEnableLatch();
data_to_send[0] = PAGE_PROGRAM;
data_to_send[1] = (page_adress >> 16) & 0xff;
data_to_send[2] = (page_adress >> 8) & 0xff;
data_to_send[3] = page_adress & 0xff;
W25Q64_Set_ChipSelect_Low();
W25Q64_SPI_Transmit_Data(data_to_send, 4);
status = W25Q64_SPI_Transmit_Data_DMA(data, size);
//W25Q64_Set_ChipSelect_High();
return status;
}
W ten prosty sposób zmodyfikowaliśmy bibliotekę pamięci W25Q64. Przejdźmy do obsługi magistrali SPI.
W funkcji inicjalizacyjnej dodajemy konfigurację DMA. Wykorzystamy jednocześnie wysyłanie danych i odbieranie, dlatego konfigurujemy dwa kanały DMA.
W przypadku wysyłania danych wybieramy kierunek transmisji z pamięci do układu peryferyjnego.Chcemy, aby adres w pamięci był inkrementowany. Dane będą 8-bitowe, zatem długość danych konfigurujemy jako BYTE.
LL_AHB1_GRP1_EnableClock(LL_AHB1_GRP1_PERIPH_DMA1);
LL_DMA_SetPeriphRequest(DMA1, LL_DMA_CHANNEL_1, LL_DMAMUX_REQ_SPI1_TX);
LL_DMA_SetDataTransferDirection(DMA1, LL_DMA_CHANNEL_1, LL_DMA_DIRECTION_MEMORY_TO_PERIPH);
LL_DMA_SetChannelPriorityLevel(DMA1, LL_DMA_CHANNEL_1, LL_DMA_PRIORITY_HIGH);
LL_DMA_SetMode(DMA1, LL_DMA_CHANNEL_1, LL_DMA_MODE_NORMAL);
LL_DMA_SetPeriphIncMode(DMA1, LL_DMA_CHANNEL_1, LL_DMA_PERIPH_NOINCREMENT);
LL_DMA_SetMemoryIncMode(DMA1, LL_DMA_CHANNEL_1, LL_DMA_MEMORY_INCREMENT);
LL_DMA_SetPeriphSize(DMA1, LL_DMA_CHANNEL_1, LL_DMA_PDATAALIGN_BYTE);
LL_DMA_SetMemorySize(DMA1, LL_DMA_CHANNEL_1, LL_DMA_MDATAALIGN_BYTE);
NVIC_SetPriority(DMA1_Channel1_IRQn, 0);
NVIC_EnableIRQ(DMA1_Channel1_IRQn);
LL_DMA_EnableIT_TC(DMA1, LL_DMA_CHANNEL_1);
Do obsługi odbierania danych skonfigurujemy kanał 2 DMA. Jako kierunek transmisji wybieramy z układu peryferyjnego do pamięci. Inkrementuje adres w pamięci oraz konfigurujemy długość danych jako BYTE.
LL_DMA_SetPeriphRequest(DMA1, LL_DMA_CHANNEL_2, LL_DMAMUX_REQ_SPI1_RX);
LL_DMA_SetDataTransferDirection(DMA1, LL_DMA_CHANNEL_2, LL_DMA_DIRECTION_PERIPH_TO_MEMORY);
LL_DMA_SetChannelPriorityLevel(DMA1, LL_DMA_CHANNEL_2, LL_DMA_PRIORITY_HIGH);
LL_DMA_SetMode(DMA1, LL_DMA_CHANNEL_2, LL_DMA_MODE_NORMAL);
LL_DMA_SetPeriphIncMode(DMA1, LL_DMA_CHANNEL_2, LL_DMA_PERIPH_NOINCREMENT);
LL_DMA_SetMemoryIncMode(DMA1, LL_DMA_CHANNEL_2, LL_DMA_MEMORY_INCREMENT);
LL_DMA_SetPeriphSize(DMA1, LL_DMA_CHANNEL_2, LL_DMA_PDATAALIGN_BYTE);
LL_DMA_SetMemorySize(DMA1, LL_DMA_CHANNEL_2, LL_DMA_MDATAALIGN_BYTE);
NVIC_SetPriority(DMA1_Channel2_3_IRQn, 0);
NVIC_EnableIRQ(DMA1_Channel2_3_IRQn);
LL_DMA_EnableIT_TC(DMA1, LL_DMA_CHANNEL_2);
Dla obu kanałów włączamy przerwania od zakończenia transferu.
W funkcji spi_write_data_dma() konfigurujemy adresy przesyłanych danych oraz ilość danych. Następnie włączamy DMA w SPI oraz uruchamiamy kanał DMA.
void spi_write_data_dma(uint8_t *data, uint32_t size)
{
tx_buffer.data_ptr = data;
tx_buffer.count = size;
LL_DMA_ConfigAddresses(DMA1, LL_DMA_CHANNEL_1, (uint32_t)tx_buffer.data_ptr, LL_SPI_DMA_GetRegAddr(SPI1), LL_DMA_GetDataTransferDirection(DMA1, LL_DMA_CHANNEL_1));
LL_DMA_SetDataLength(DMA1, LL_DMA_CHANNEL_1, tx_buffer.count);
LL_SPI_EnableDMAReq_TX(SPI1);
LL_DMA_EnableChannel(DMA1, LL_DMA_CHANNEL_1);
LL_SPI_Enable(spi);
}W przypadku odbierania danych musimy skonfigurować zarówno nadawanie, jak i odbieranie. Do transferu danych musimy podać adres do bufora danych o takiej samej długości, jak ilość danych, które chcemy odebrać. Żeby nie tworzyć dodatkowego buforu z DUMMY BYTES lub rekonfigurować DMA, podamy tutaj ten sam bufor co z danymi odbieranymi. W końcu wszystko jedno co wyślemy 🙂
void spi_read_data_dma(uint8_t *data, uint32_t size)
{
tx_buffer.data_ptr = data;
tx_buffer.count = size;
rx_buffer.data_ptr = data;
rx_buffer.count = size;
LL_DMA_ConfigAddresses(DMA1, LL_DMA_CHANNEL_1, (uint32_t)tx_buffer.data_ptr, LL_SPI_DMA_GetRegAddr(spi), LL_DMA_GetDataTransferDirection(DMA1, LL_DMA_CHANNEL_1));
LL_DMA_SetDataLength(DMA1, LL_DMA_CHANNEL_1, tx_buffer.count);
LL_DMA_ConfigAddresses(DMA1, LL_DMA_CHANNEL_2, LL_SPI_DMA_GetRegAddr(spi), (uint32_t)rx_buffer.data_ptr, LL_DMA_GetDataTransferDirection(DMA1, LL_DMA_CHANNEL_2));
LL_DMA_SetDataLength(DMA1, LL_DMA_CHANNEL_2, rx_buffer.count);
LL_SPI_EnableDMAReq_TX(spi);
LL_DMA_EnableChannel(DMA1, LL_DMA_CHANNEL_1);
LL_SPI_EnableDMAReq_RX(spi);
LL_DMA_EnableChannel(DMA1, LL_DMA_CHANNEL_2);
LL_SPI_Enable(spi);
}W funkcjach DMA_Channel1_IRQHandler() i DMA_Channel2_3_IRQHandler() dodajemy sprawdzenie flag przerwania od DMA i wywołujemy obsługę zakończenia transferu.
void DMA_Channel1_IRQHandler(void)
{
if (LL_DMA_IsActiveFlag_TC1(DMA1))
{
LL_DMA_ClearFlag_TC1(DMA1);
spi_dma_transmit_callback();
}
}
void DMA_Channel2_3_IRQHandler(void)
{
if (LL_DMA_IsActiveFlag_TC2(DMA1))
{
LL_DMA_ClearFlag_TC2(DMA1);
spi_dma_receive_callback();
}
}W obsłudze zakończenia transferu DMA wyłączamy kanały DMA i odpowiednio DMA w SPI. Potem w zależności od trybu pracy (nadawanie czy odbieranie) wywołujemy sekwencję czyszczenia kolejek i oczekiwania na flagę BUSY. Pamiętamy też o ustawieniu w stan wysoki linii Chip Select.
void spi_dma_transmit_callback(void)
{
LL_SPI_DisableDMAReq_TX(SPI1);
LL_DMA_DisableChannel(DMA1, LL_DMA_CHANNEL_1);
if(!LL_SPI_IsEnabledDMAReq_RX(spi))
{
while (LL_SPI_GetTxFIFOLevel(spi) != LL_SPI_TX_FIFO_EMPTY)
;
while (LL_SPI_IsActiveFlag_BSY(spi) != 0)
;
LL_SPI_Disable(spi);
while (LL_SPI_GetRxFIFOLevel(spi) != LL_SPI_RX_FIFO_EMPTY)
{
LL_SPI_ReceiveData8(spi);
}
LL_SPI_ClearFlag_OVR(spi);
spi_cs_set_high();
spi_transfer_cplt_callback(TRANSMIT);
}
}
void spi_dma_receive_callback(void)
{
LL_SPI_DisableDMAReq_RX(SPI1);
LL_DMA_DisableChannel(DMA1, LL_DMA_CHANNEL_2);
while (LL_SPI_GetTxFIFOLevel(spi) != LL_SPI_TX_FIFO_EMPTY)
;
while (LL_SPI_IsActiveFlag_BSY(spi) != 0)
;
LL_SPI_Disable(spi);
while (LL_SPI_GetRxFIFOLevel(spi) != LL_SPI_RX_FIFO_EMPTY)
{
LL_SPI_ReceiveData8(spi);
}
LL_SPI_ClearFlag_OVR(spi);
spi_cs_set_high();
spi_transfer_cplt_callback(RECEIVE);
}Działanie programu przetestujemy w analogiczny sposób, jak dla trybu przerwań Dodamy trzy bufory – dwa do przechowywania odebranych danych oraz jeden do wysyłanych.
#define SIZE_BUFFER 256
uint8_t read_buffer_1[SIZE_BUFFER];
uint8_t read_buffer_2[SIZE_BUFFER];
uint8_t write_buffer[SIZE_BUFFER];
Bufor nadawczy wypełnimy kolejnymi liczbami naturalnymi.
for (uint32_t i = 0; i < SIZE_BUFFER; i++)
{
write_buffer[i] = i;
}Inicjalizujemy interfejs SPI oraz pamięć W25Q64.
spi_init();
W25Q64_Init();Czyścimy zerowy sektor, do którego zapiszemy dane.
W25Q64_SectorErase(0);Teraz przy pomocy prostej maszyny stanów odczytamy dane po wyczyszczeniu (powinny być w niej same 0xFF). Następnie zapiszemy dane i odczytamy je ponownie. Porównamy dwa bufory z danymi przez zapisem i po zapisie.
while (1)
{
if(state == READ_1)
{
state = WAIT;
W25Q64_ReadDataBytes(0x0000, read_buffer_1, SIZE_BUFFER);
}
else if(state == WRITE)
{
state = WAIT;
W25Q64_PageProgram(0x0000, write_buffer, SIZE_BUFFER);
}
else if(state == READ_2)
{
state = STOP;
W25Q64_ReadDataBytes(0x0000, read_buffer_2, SIZE_BUFFER);
}
}Definicje stanów umieściłem w enumie.
typedef enum
{
READ_1 = 0,
WRITE,
READ_2,
WAIT,
STOP
}state_t;
Zmiana stanu będzie odbywała się w callback-u od zakończenia transmisji SPI.
void spi_transfer_cplt_callback(transfer_type_t type)
{
if(type == TRANSMIT && state == WAIT)
{
state = READ_2;
}
else if(type == RECEIVE && state == WAIT)
{
state = WRITE;
}
}Teraz możemy wgrać i uruchomić program w trybie Debug. Po wykonaniu wszystkich operacji (czas trwania nie powinien być dłuższy niż kilka milisekund), możemy zobaczyć efekt w postaci danych dwóch buforów odbiorczych. Bufor pierwszy będzie zawierał wyczyszczoną pamięć (0xFF), a bufor drugi dane zapisane do pamięci.


Chciałbyś otrzymywać na bieżąco informacje o nowych artykułach z kursu? Zapisz się do newslettera!
TO NIE TYLKO MAIL Z INFORMACJĄ O NOWEJ LEKCJI, ALE TAKŻE DODATKOWE MATERIAŁY. NIE PRZEGAP NOWEJ TREŚCI I DODATKOWYCH BONUSÓW. PRZEJDŹ DO STRONY KURSU I PODAJ SWÓJ ADRES E-MAIL. NIE ZAPOMNIJ POTWIERDZIĆ CHĘCI DOŁĄCZENIA W PIERWSZEJ WIADOMOŚCI!
Nad jakim nowym cyklem teraz pracujesz? (Wspominasz o tym w komentarzu wyżej).
I pytanko – jesteś pewien, że te pętle while(); to dobry pomysł w callbackach?
Aktualnie przygotowuje serię o BLE. Pojawiły się już pierwsze artykuły. Co do while, w docelowym programie na pewno warto to rozwiązać np. przy zastosowaniu dodatkowo timeoutow. W kursie pokazuję podstawy obsługi, na pewno niektóre rzeczy są w sporym uproszczeniu, ale nie wszystko da się omówić od razu.
Kiedy następny?
Wstępnie zaplanowane miałem te 8 rozdziałów. Mam trochę materiału na kolejne lekcje, więc pewnie się za jakiś czas pojawią, ale w tej chwili przygotowuję trochę inny cykl, także nie jestem w stanie określić dokładnie kiedy wrócimy do Kursu LL. Polecam zapisać się na newsletter, to na pewno otrzymasz informację, jak się coś pojawi 🙂