Współdzielenie danych – volatile, operacje atomowe i sekcja krytyczna

W dzisiejszym dynamicznym środowisku systemów embedded, współdzielenie danych stanowi kluczowy element efektywnego funkcjonowania aplikacji wbudowanych. W miarę wzrostu złożoności tych systemów, konieczność synchronizacji i współpracy pomiędzy różnymi komponentami staje się coraz bardziej paląca. Wprowadzenie pojęć takich jak „volatile”, „operacje atomowe” i „sekcje krytyczne” nabiera zatem szczególnego znaczenia w kontekście optymalizacji wydajności i zapewnienia niezawodności w środowisku embedded. W niniejszym artykule przyjrzymy się bliżej tym kluczowym koncepcjom, analizując ich rolę w procesie współdzielenia danych oraz ich wpływ na bezpieczeństwo i stabilność systemów embedded.
Problem współdzielenia danych
Problem współdzielenia danych w systemach embedded wynika głównie z konieczności synchronizacji dostępu do zasobów współdzielonych przez różne komponenty systemu. W przypadku systemów wbudowanych, gdzie zasoby są zazwyczaj ograniczone, a efektywność działania systemu jest kluczowa, konieczność współdzielenia danych staje się nieunikniona.
W kontekście wątków głównych i obsługi przerwań, pojawia się specyficzny problem związany z asynchronicznym charakterem przerwań. Wątek główny może być przerwany w dowolnym momencie przez obsługę przerwania, co tworzy potencjalne zagrożenie dla danych współdzielonych. Szczególnie delikatną sytuacją jest współdzielenie zmiennych między wątkiem głównym a obsługą przerwania.
W przypadku braku odpowiedniej synchronizacji, może dojść do sytuacji, gdzie wątek główny i obsługa przerwania równocześnie próbują modyfikować tę samą zmienną. To zjawisko nazywane jest wyścigiem (ang. race condition) i może prowadzić do nieprzewidywalnych i niepożądanych efektów, takich jak utrata danych, błędy w działaniu systemu lub nawet jego awaria.
Aby uniknąć tego rodzaju problemów, konieczne jest zastosowanie odpowiednich mechanizmów synchronizacji, takich jak sekcje krytyczne, operacje atomowe czy też stosowanie odpowiednich flag, które informują o dostępie do danych. Warto również zwrócić szczególną uwagę na stosowanie zmiennych oznaczonych jako „volatile”, co informuje kompilator, że zmienna może być modyfikowana przez różne części programu, w tym obsługę przerwań. Dzięki odpowiedniemu zarządzaniu dostępem do danych, można skutecznie minimalizować ryzyko konfliktów i zagwarantować niezawodność systemu embedded.
Do czego tak właściwie służy modyfikator „volatile”?
Modyfikator volatile w języku programowania, jakim jest C, informuje kompilator, że zmienna może zostać zmodyfikowana w sposób niewidoczny dla danego fragmentu kodu. Kompilator w przypadku użycia modyfikatora nie powinien dokonywać pewnych optymalizacji związanych z dostępem do tej zmiennej, które mogłyby zakładać stałość wartości zmiennej.
Oznacza to, że jeżeli w funkcji wykonujemy tylko odczyt zmiennej, a nie zmieniamy jej wartości, to kompilator może uznać, że nie ma potrzeby odczytywania wartości tej zmiennej za każdym razem. W takim wypadku wartość będzie przechowywana na stosie i pobierana z tego miejsca, a nie z pamięci, gdzie ona faktycznie jest zapisana. Może to spowodować sytuację, że jeżeli wartość tej zmiennej zostanie zmodyfikowana w zupełnie innym miejscu programu, zoptymalizowana funkcja nie będzie wiedziała o tej zmianie.
Służąc głównie w kontekście programowania w systemach wbudowanych, modyfikator volatile jest używany w sytuacjach, gdzie zmienna może być modyfikowana przez coś innego niż sam program, na przykład przez obsługę przerwań, sprzęt lub inne wątki. Istotne jest zrozumienie, że kompilator może dokonywać pewnych optymalizacji, zakładając, że wartość zmiennej nie zmieni się w sposób niewidoczny w danym fragmencie kodu. Dla zmiennych oznaczonych jako volatile, kompilator nie dokonuje tych optymalizacji, co zapewnia bardziej precyzyjne zarządzanie dostępem do zasobów współdzielonych. Zastosowanie volatile spowoduje, że za każdym razem wartość zmiennej będzie pobrana z pamięci, gdzie ta zmienna jest umieszczona.
Przykłady sytuacji, w których warto użyć modyfikatora volatile:
- Obsługa przerwań – jeżeli zmienna jest modyfikowana w obszarze obsługi przerwań, konieczne jest oznaczenie jej jako volatile, aby uniknąć błędów związanych z optymalizacjami kompilatora.
- Komunikacja między wątkami – jeżeli zmienna jest współdzielona między różnymi wątkami, a dostęp do niej nie jest zabezpieczony za pomocą semaforów czy innych mechanizmów synchronizacyjnych, to oznaczenie jej jako volatile może być konieczne.
- Komunikacja zewnętrzna – gdy zmienna jest modyfikowana przez sprzęt lub inne procesy spoza kontrolowanego obszaru kodu, volatile może być stosowane dla zapewnienia poprawnego dostępu do tych danych.
Ważne jest jednak ostrożne korzystanie z modyfikatora volatile, ponieważ nadmierne użycie może prowadzić do utraty optymalizacji kompilatora i wpływać negatywnie na wydajność kodu. Dlatego modyfikator powinien być stosowany tylko w sytuacjach, gdzie rzeczywiście istnieje potrzeba zapewnienia niezmienności dostępu do zmiennej w kontekście współdzielenia danych. Pamiętaj, że nie powinno się dodawać nic w kodzie „na zapas”.
Zastosowanie volatile w praktyce – przykład
Na wstępnie tylko wspomnę, że wszystkie przykłady uruchamiałem na mikrokontrolerze STM32L476RGT6 na płytce Nucleo-L476RG. Programy powinny jednak działać analogicznie na innych układach z rdzeniem ARM Cortex-M4.
Przeanalizujmy przykład, kiedy volatile pozwoli nam zapewnić prawidłowe współdzielenie danych, a co za tym idzie działanie programu. Wyobraźmy sobie sytuację, że mamy pętlę główną programu, w której odczytujemy wartość zmiennej counter. Jeżeli jest ona większa od 10, resetujemy ją (przypisujemy jej wartość 0) i zwiększamy licznik reset_cnt.
while (1)
{
if (counter > 10)
{
counter = 0;
reset_cnt++;
}
}Zmienną counter będziemy inkrementować w przerwaniu od timera wywoływanego co 100 ms.
void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef *htim)
{
counter++;
}Zmienne counter i reset counter deklarujemy jako globalne (umieszczamy przed funkcją main).
int counter = 0;
int reset_cnt = 0;Jak widzisz, na razie nie używam modyfikatora volatile. Po uruchomieniu programu i odczekaniu kilku sekund możemy zobaczyć, że zmienna counter prawidłowo jest zerowana, a reset_cnt została zwiększona.
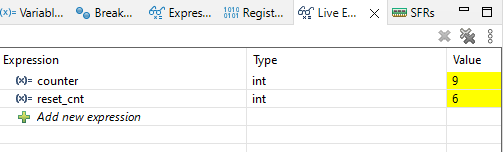
Czy to oznacza, że volatile nie jest tutaj potrzebne? Niestety możemy tutaj ulec złudzeniu, że program działa poprawnie. Ale kod nie jest prawidłowy. Zmieńmy optymalizację na flagę -O3. Co otrzymamy teraz po uruchomieniu programu?
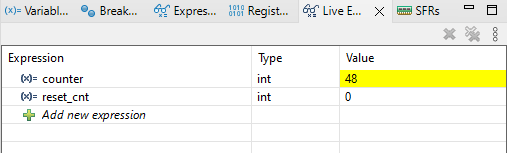
Zmienna counter nie jest resetowana, a reset_cnt nie został zwiększony. Można byłoby powiedzieć, że optymalizacja zepsuła nam program. Prawda jest jednak inna – to my go źle napisaliśmy. Kod programu powinniśmy pisać tak, aby działał przy różnych flagach optymalizacji. Dzięki temu w przypadku, gdy będziemy potrzebowali dodać optymalizację w celu zmniejszenia objętości kody wynikowego lub przyspieszenia działania programu, nie spotkamy się z przykrą niespodzianką.
Ale co się właściwie wydarzyło? Kompilator, chcąc zoptymalizować kod, uznał, że zmienna counter jest tylko odczytywana (nie widzi inkrementacji w przerwaniu), dlatego nie ma potrzeby aktualizować jej wartości i dlatego w instrukcji warunkowej zawsze pod counter podstawia wartość 0. Jak to naprawić? W tym przypadku zabrakło właśnie modyfikatora volatile. Dodajmy więc volatile do zmiennej counter, oczywiście zostawiamy flagę optymalizacji -O3, i ponownie uruchomimy program. Teraz program działa nam prawidłowo.
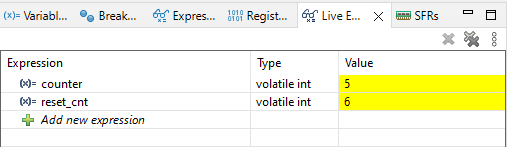

Czy volatile to rozwiązanie wszystkich problemów?
W większości przypadków i aplikacji pisanych hobbystycznie (a nawet komercyjnie, jeżeli nie są to projekty wymagające krytycznego poziomu bezpieczeństwa) moglibyśmy na tym etapie zakończyć nasze rozważania na temat współdzielenia danych między wątkiem głównym a przerwaniem. Jednak modyfikator volatile nie jest receptą na wszystkie problemy i warto być tego świadomym. O co mi chodzi? Przeanalizujmy inny przypadek.
Teraz zmienną counter będziemy zwiększać w pętli głównej, a w przerwaniu zapisywać stan zmiennej do tablicy counter_tab[].
while (1)
{
counter++;
}void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef *htim)
{
counter_tab[reset_cnt] = counter;
counter = 0;
reset_cnt++;
if (reset_cnt >= 10)
{
reset_cnt = 0;
}
}Co otrzymamy po uruchomieniu programu? Oczekujemy, że w tablicy pojawią się zbliżone do siebie, albo takie same liczby. Jednak wynik jest zupełnie inny. Spójrz na grafikę poniżej.
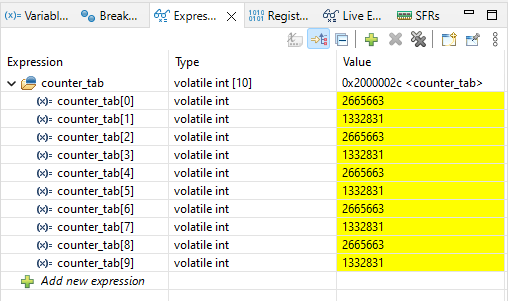
W tablicy counter_tab[] pojawiły się liczby określające ilość przejść w pętli głównej, ale są one różne od siebie. Można jednak dostrzec, że nie są one przypadkowe – 1332831 jest dwa razy mniejsze od 2665663 (w przybliżeniu). Która liczba jest prawidłowa? Program działa nam niepoprawnie, bo powinien za każdym razem zapisywać taką samą (lub zbliżoną) wartość. I nie ważne czy dodasz tutaj volatile, albo ustawisz flagę optymalizacji -O0 – efekt będzie podobny (z tym, że przy różnych poziomach optymalizacji możemy otrzymywać różne ilości przejść pętli). Co w takim razie dzieje się w programie i dlaczego nie działa prawidłowo? Problemem jest tzw. wyścig.
Wyścig (race condition)
Wyścig (race condition) w kontekście współdzielenia danych w systemach embedded występuje, gdy dwa lub więcej wątków lub procesów jednocześnie próbują równocześnie odczytać lub modyfikować tę samą współdzieloną zmienną lub zasób. Problem ten wynika z braku synchronizacji dostępu do danych, co może prowadzić do nieprzewidywalnych i niepożądanych efektów. W przypadku systemów embedded, gdzie zasoby są zazwyczaj ograniczone, a działanie systemu musi być precyzyjnie kontrolowane, wyścigi stanowią szczególne zagrożenie. Wątki w systemach embedded mogą być m.in. wątkami obsługującymi przerwania, zadania w czasie rzeczywistym, czy też wątkami obsługującymi komunikację z zewnętrznymi urządzeniami.
W naszym przypadku wątek główny cały czas zwiększa wartość zmiennej counter, a przerwanie co 100 ms resetuje wartość zmiennej. Operacja inkrementacji nie jest wykonywana w jednym cyklu procesora i może zdarzyć się tak, że wątek główny pobierze wartość counter – w międzyczasie timer przerwie pracę głównego wątku i wyzeruje zmienną – a wątek główny potem dokończy swoją operację tzn. zwiększy wartość o jeden i znów zapisze ją do adresu zmiennej. W efekcie w pamięci będzie wartość pobrana przed operacją (zwiększona o jeden), a nie wyzerowana przez przerwanie. Sytuację tą obrazuje grafika poniżej. Przedstawione działanie jest pewnie mocno uproszczone, ale myślę, że zachowuje ideę i pozwoli Ci zauważyć problem, z jakim się zmagamy.

Jak sobie z czymś takim poradzić? Jeśli volatile nie wystarcza, to trzeba sięgnąć po cięższe działa 🙂
Operacje atomowe i sekcja krytyczna
Aby zapobiec wyścigom, musimy wykorzystać dodatkowe mechanizmy. Do takich należą operacje atomowe i sekcja krytyczna. Najpierw krótko wyjaśnię, czym są te dwa pojęcia.
Operacje atomowe to operacje, które są wykonywane jako jedna, niepodzielna jednostka, niezależnie od innych operacji wykonywanych równocześnie w systemie. Oznacza to, że operacje te są niemożliwe do przerwania w trakcie ich wykonywania. W kontekście współdzielenia danych w programowaniu równoległym lub wielowątkowym, operacje atomowe zapewniają, że operacje na współdzielonych zmiennych są bezpieczne i nie prowadzą do wyścigów. Implementacja operacji atomowych zazwyczaj korzysta z specjalnych instrukcji procesora lub mechanizmów zapewniających jednoczesne wykonanie operacji w sposób niepodzielny.
Sekcja krytyczna to fragment kodu, w którym występuje dostęp lub modyfikacja współdzielonych zasobów, takich jak zmienne lub struktury danych, i który musi być wykonywany atomowo, czyli bez możliwości jednoczesnego dostępu przez inne wątki. Aby uniknąć wyścigów i zagwarantować poprawność współdzielenia danych, programiści stosują sekcje krytyczne.
Mechanizm sekcji krytycznej polega na zastosowaniu odpowiednich operacji synchronizacyjnych, takich jak semafory, muteksy (mutex), czy instrukcje atomowe. W praktyce, przed wejściem do sekcji krytycznej wątek musi uzyskać dostęp do odpowiedniego mechanizmu synchronizacyjnego, a po zakończeniu operacji zwolnić ten dostęp. Dzięki temu zapewnia się, że tylko jeden wątek może jednocześnie znajdować się w sekcji krytycznej, eliminując ryzyko współbieżnego dostępu i ewentualnych konfliktów.
Oba pojęcia są więc ze sobą powiązane. Sekcja krytyczna to fragment kodu, gdzie występuje modyfikacja współdzielonych zmiennych. Aby zaimplementować sekcję krytyczną, używamy m.in. operacji atomowych.
Operacje atomowe w C
W języku C, operacje atomowe są obsługiwane poprzez bibliotekę stdatomic.h, wprowadzoną w standardzie C11. Biblioteka ta dostarcza typy danych oraz operacje, które są wykonywane atomowo, eliminując ryzyko wyścigów w programach wielowątkowych. Aby z niej korzystać musimy się upewnić, że kompilator korzysta minimum ze standardu C11 (może być wyższy). W przypadku STM32CubeIDE standard języka wybieramy w zakładce Project -> Properties -> C/C++Build -> Settings, a następnie Tool Settings -> MCU GCC Compiler -> General.

Wśród definicji dostępnych w bibliotece znajdziemy m.in. typy danych z oznaczeniem „_Atomic”. Aby zmienna była atomowa, możemy dodać przed nią modyfikator _Atomic np.
_Atomic int var = 0;lub skorzystać z typów zmiennych atomowych np.
atomic_int var = 0;Nie do wszystkich typów zmiennych, a w szczególności stosowanych w embedded znajdziemy bezpośredni odpowiednik. W przypadku zmiennych uint32_t musimy np. zastosować typ atomic_uint_least32_t lub atomic_uint_fast32_t.
Poza wybraniem odpowiedniego typu zmiennej, powinniśmy skorzystać również z dedykowanych funkcji do obsługi operacji atomowych. Wśród nich znajdziemy:
- atomic_init – inicjuje istniejący obiekt atomowy
- atomic_store lub atomic_store_explicit – zapisuje wartość w obiekcie atomowym
- atomic_load lub atomic_load_explicit – pobiera wartość z obiektu atomowego
Poza trzema podstawowymi, mamy do dyspozycji jeszcze kilka dodatkowych funkcji:
- atomic_exchange lub atomic_exchange_explicit – zamienia wartość z wartością obiektu atomowego
- atomic_fetch_add lub atomic_fetch_add_explicit – dodawanie liczby do wartości atomowej
- atomic_fetch_sub lub atomic_fetch_sub_explicit – odejmowanie liczby od wartości atomowej
- atomic_fetch_or, atomic_fetch_xor, atomic_fetch_and – operacje bitowe na obiektach atomowych
- atomic_flag_test_and_set i atomic_flag_clear – ustawienie wartości true i flase we flagach
W przypadku funkcji z przyrostkiem „explicit” mamy możliwość wyboru kolejność pamięci, która decyduje o widoczności operacji dla innych wątków. W funkcjach bez tego przyrostka domyślnie korzystamy z „memory_order_seq_cst”. Więcej szczegółów na ten temat możesz znaleźć w dokumentacji biblioteki.
Warto pamiętać, że nie wszystkie operacje są dostępne na wszystkie rdzenie. Mniejsze rdzenie np. ARM Cortex-M0 i ARM Cortex-M0+ mogę nie wspierać obsługi operacji dodawania czy odejmowania.
Operacje atomowe powinny być stosowane w przypadkach, gdy mamy do czynienia z wielowątkowym lub współbieżnym kodem, a dostęp do współdzielonych zasobów (takich jak zmienne) musi być bezpieczny i niepodzielny. Przykładami takich scenariuszy jest m.in.:
- Współbieżny dostęp do współdzielonych zmiennych – w przypadku, gdy kilka wątków jednocześnie odczytuje i/lub modyfikuje tę samą zmienną, używanie operacji atomowych może chronić przed wyścigami.
- Operacje na licznikach – wielowątkowe zwiększanie (inkrementacja) lub zmniejszanie (dekrementacja) liczników, takich jak liczby referencyjne czy ilości dostępnych zasobów, wymaga operacji atomowych. Dzięki nim można uniknąć konfliktów, które mogą wystąpić, gdy kilka wątków jednocześnie próbuje zmienić wartość licznika.
- Flagi sygnalizacyjne – gdy używamy flag sygnalizacyjnych do komunikacji między wątkami, operacje atomowe są niezbędne. Przykładowo, ustawianie, czytanie lub zerowanie flagi sygnalizacyjnej w sposób atomowy jest kluczowe, aby uniknąć błędów związanych z asynchronicznym dostępem.
- Algorytmy zabezpieczone przed zakleszczeniem (deadlock) – w przypadku, gdy stosujemy algorytmy zabezpieczające przed zakleszczeniem, operacje atomowe są często używane do wykonania kroków algorytmu w sposób bezpieczny pod względem współbieżności.
- Optymalizacja kodu dla wielowątkowości – w niektórych przypadkach, zwłaszcza w kodzie, który ma dużo operacji na współdzielonych zmiennych, operacje atomowe mogą być używane do zoptymalizowania kodu, eliminując konieczność stosowania bardziej zaawansowanych mechanizmów synchronizacyjnych.
Operacje atomowe w języku C, takie jak te dostarczane przez bibliotekę stdatomic.h, są skonstruowane tak, aby były bezpieczne w kontekście współbieżności. Jednak zawsze należy stosować je z umiarem i tylko tam, gdzie jest to faktycznie konieczne, ponieważ operacje atomowe mogą wpływać na wydajność i złożoność kodu.
Zastosowanie stdatomic.h w praktyce – przykład
Wiemy już na czym stoimy. Nasz scenariusz idealnie pasuje do zastosowania operacji atomowych. Dodajmy je zatem do naszego kodu.
W pierwszej kolejności załączamy bibliotekę „stdatomic.h”.
#include <stdatomic.h>Teraz dodajemy zmienną typu atomic. Możemy ją łączyć z modyfikatorem volatile.
volatile atomic_int counter = 0;W głównym wątku, zamiast zwykłej inkrementacji, stosujemy dodawanie atomowe.
atomic_fetch_add(&counter, 1);A na koniec dodajemy operacje atomowe odczytu i zapisu w przerwaniu.
void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef *htim)
{
counter_tab[reset_cnt] = atomic_load(&counter);
atomic_store(&counter, 0);
reset_cnt++;
if (reset_cnt >= 10)
{
reset_cnt = 0;
}
}Jak będzie wyglądało działanie programu po tych zmianach. Uruchamiamy!
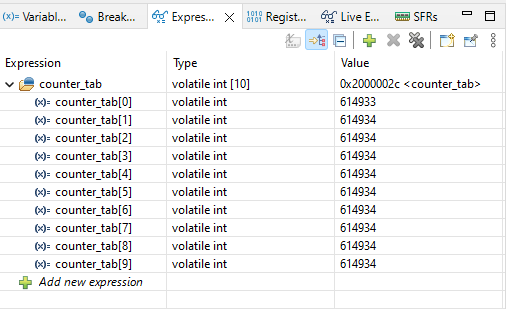
Teraz wszystko działa jak powinno. Widzimy, że pętla główna wykonuje się teraz kilka razy wolniej. O tym wspominałem w poprzednim akapicie – operacje atomowe mogą wpływać na wydajność i złożoność kod, dlatego należy je stosować tylko tam, gdzie jest to potrzebne.
A co jeśli mi działa bez operacji atomowych?
W większości przypadków do „prawidłowej” pracy programu wystarczy użycie modyfikatora volatile. Dlaczego? Ponieważ sytuacja, która wywołałem w przykładzie zachodzi bardzo, bardzo rzadko. Jeżeli w pętli głównej wykonuje się dużo kodu, to istnieje stosunkowo małe prawdopodobieństwo, że wystąpi wyścig. Dodatkowo często nawet nie zauważymy, że coś się zepsuło, jeżeli nasza hobbystyczna aplikacja nie wykonuje krytycznych operacji.
Nie oznacza to jednak, że problem nie występuje. Owszem, występuje, i jeżeli chcesz być w 100% pewny, że w każdym przypadku program zadziała poprawnie i będzie stabilnie działał, to warto operacje atomowe stosować. To, że nie widać błędów na pierwszy rzut oka, nie znaczyć, że nie wystąpią kiedyś w najmniej spodziewanym momencie.
Jeżeli jednak Twoja aplikacja nie wymaga tak bardzo niezawodności, prawdopodobnie obędziesz się bez dodawania biblioteki stdatomic.h. Warto jednak wiedzieć, że volatile odpowiada za coś zupełnie innego niż stdatomic.h i być świadomym, gdzie może leżeć problem, gdy coś dziwnego zacznie się dziać w aplikacji.
Podsumowanie
Współdzielenie danych w aplikacjach embedded stanowi kluczowy element projektowania systemów wbudowanych, gdzie efektywna komunikacja między różnymi komponentami jest nieodzowna. W artykule przyjrzeliśmy się głównym wyzwaniom związanym z tym procesem, koncentrując się na konieczności zapewnienia bezpiecznego i niezawodnego dostępu do współdzielonych zasobów. Omówiłem pojęcia takie jak „volatile”, operacje atomowe i sekcje krytyczne, które są kluczowe dla eliminacji wyścigów (race conditions) oraz zagwarantowania poprawnego funkcjonowania systemów embedded. Pokazałem także na przykładach, do czego prowadzi zaniedbanie tych aspektów.
Myślę, że w sporym stopniu wyczerpaliśmy problematykę współdzielenia zmiennych między wątkiem głównym i przerwaniami. Jeżeli podobał Ci się wpis lub masz jakieś własne przemyślenia, zostaw komentarz. Pamiętaj też, aby polubić mój profil na Facebook-u oraz zasubskrybować kanał na YouTube.